When a large language model returns a confident verdict - “this document is fraudulent”, “this alert is benign”, “this transaction is safe” - the natural instinct is to trust it. The model wrote a fluent rationale, cited the right fields, and reached a clean conclusion. The problem is that fluency is not correctness. In a low-stakes setting, an occasional wrong answer is noise. In a high-stakes pipeline, where a single verdict can deny someone a job, close a critical security incident, or release a fraudulent payment, the cost of a confident wrong answer is real and asymmetric.
This article describes a pattern that addresses that asymmetry: the judge pattern. Instead of trusting one model’s output, you route the high-impact decisions through a second, independent model whose only job is to review the first verdict against a structured rubric. The judge does not redo the work from scratch. It scrutinizes the conclusion, agrees or overrides, and explains itself. The pattern is domain-agnostic, but it is most valuable exactly where mistakes are expensive.
Why Single-LLM Verdicts Fail in High-Stakes Pipelines
Three failure modes recur often enough to design against them directly.
The first is fact hallucination. The model asserts something the evidence does not support: a date that was never in the source, an employer that does not appear in the document, a CVE that does not match the log line. The assertion is delivered in the same confident register as a correct one, so a downstream reader has no signal that it is fabricated.
The second is rubric drift. When the same model evaluates many cases across many calls, its internal sense of where the threshold sits wanders. One borderline case is scored as high-risk, an almost identical one a few calls later is scored as low-risk. There is no stable, externalized standard - just whatever the model felt about each input in isolation. Over a large batch, this drift produces inconsistent decisions that are hard to audit and harder to defend.
The third is overconfidence. Models tend to express high certainty even when the underlying evidence is thin or contradictory. Calibration - the alignment between stated confidence and actual accuracy - is generally poor, and it degrades fastest on exactly the ambiguous cases where you most need a hedge.
The tempting fix is to ask the same model again, perhaps with a different temperature or a “are you sure?” follow-up. This does not buy real independence. The second answer is drawn from the same weights, the same training distribution, and often the same prompt framing. When the first answer was wrong because of a systematic bias - a tendency to over-read a particular phrase, say - the second answer is likely to be wrong in the same direction. The errors are correlated, not independent, so averaging them or taking a majority vote does not cancel them out. Genuine cross-checking requires a different vantage point: a different model, a different prompt, and crucially, no exposure to the first model’s reasoning.
Roles, Not Models: A Tiered Architecture
The instinct when reliability matters is to reach for “a smarter model” everywhere. That is expensive and it misses the point. The more useful framing is to assign each tier a job and pick the cheapest model that can do that job well. A capable model wasted on mechanical extraction is money burned; a cheap model asked to make a final high-stakes call is risk taken on.

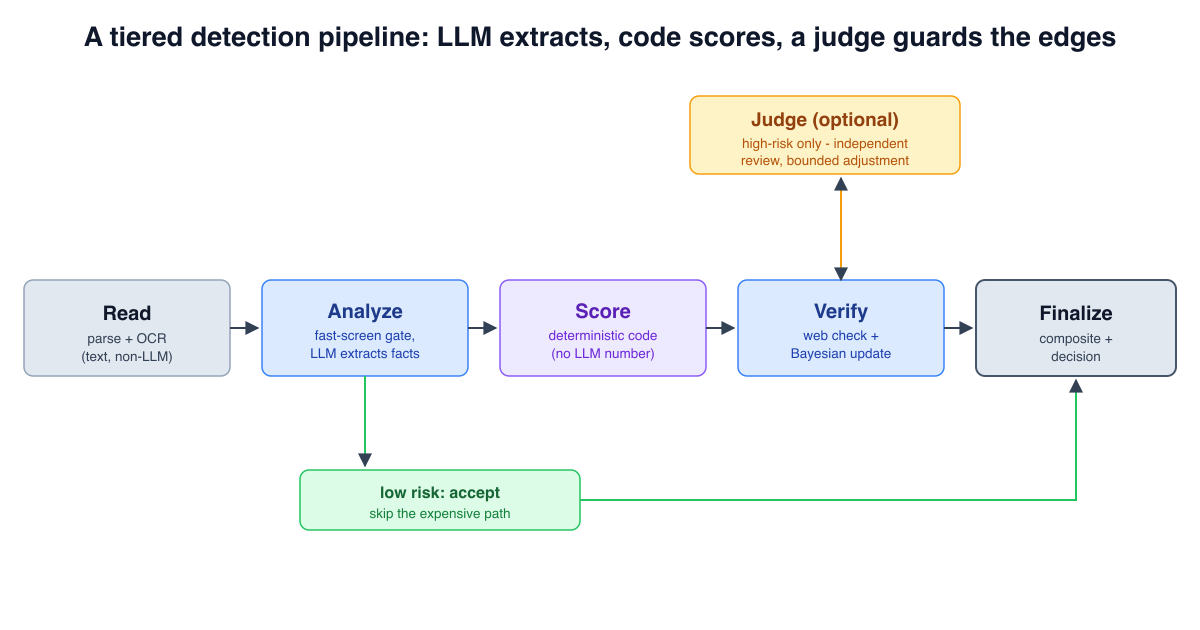{kind=link}
A tiered pipeline: each stage has one job, the score is computed by deterministic code rather than by the model, and an optional judge re-checks only the high-risk cases.
Each stage has a distinct contract, and they are not all model calls. Reading comes first and is not an LLM step at all: a parser pulls text out of the document, falling back to OCR when the file is a scan or a photo with no text layer. Only then does a model see anything. A cheap fast screen scores every case and acts as a gate - cases that are clearly low-risk are accepted as-is and skip everything downstream, which is where most of the cost savings come from. Cases that are not cleared escalate to a capable analysis model whose job is to extract structured facts and surface concerns, ideally with an extended thinking budget because this is where the ambiguity concentrates. Crucially, the analysis model does not produce the final number: a deterministic scoring step in ordinary code maps the extracted facts to a risk score, so the same facts always yield the same score. A verification step then checks the claimed entities against external sources and nudges the score with a Bayesian update. Only after all of that, and only on the cases that are still high-risk, does the judge run.
The value of this separation is twofold. It controls cost, because the most capable model only runs where its judgment is actually needed. And it controls error propagation, because each tier’s output is constrained and checkable rather than a single opaque end-to-end call. The same idea shows up in security tooling: in Wazuh + AWS Bedrock: AI Security in Docker (Part 1) the pipeline separates retrieval, query generation, and synthesis into distinct tool-mediated steps rather than asking one model to do everything at once.
The Judge Agent: Independent Inputs, Structured Rubric
The judge agent is the heart of the pattern, and its design has one rule that matters above all others: the judge sees the same evidence as the primary model, but it does not see the primary model’s chain of thought. If you hand the judge the primary’s reasoning, you have not built a reviewer - you have built a rubber stamp. The judge reads a persuasive narrative that already reaches a conclusion and anchors on it, and you lose the independence that was the entire point.
So the judge receives the evidence and the primary outputs it is meant to check - the computed scores and the verification results - but not the analysis model’s chain of thought. It evaluates them against an explicit, externalized rubric: a written standard for what counts as high-risk, what evidence each conclusion requires, and what the disqualifying conditions are. It then emits a small, structured output: whether it agrees, a bounded adjustment to the score when it disagrees, and a rationale. The adjustment is deliberately capped, so a single judge call can nudge a verdict but never unilaterally flip it - the judge is a check on the pipeline, not a new single point of failure.
def judge_review(evidence: dict, scores: dict, verification: dict) -> dict:
"""Independent review, fired only on high-risk cases. The judge sees
the evidence, the computed scores, and the verification results, but
never the analysis model's chain of thought - otherwise it just
rubber-stamps. Its score adjustment is clamped so one call cannot
flip a verdict on its own."""
prompt = build_judge_prompt(evidence, scores, verification)
review = call_model(JUDGE_MODEL, prompt, rubric=JUDGE_RUBRIC)
return {
"agrees": review.agrees,
"score_delta": clamp(review.score_delta, -CAP, +CAP),
"rationale": review.rationale,
}
Three design choices in this skeleton are load-bearing. First, the rubric is passed in as an explicit parameter rather than baked into the model’s general sense of judgment. This is the direct countermeasure to rubric drift: the standard lives outside the model, in version-controlled text you can review, test, and change deliberately. Second, the output is structured, not prose - the judge commits to agrees, to a concrete score_delta, and to a rationale, which makes the review machine-readable, auditable, and trivial to log. Third, the adjustment is clamped to a fixed cap: the judge can move a borderline verdict but cannot single-handedly overturn the deterministic score, so adding it reduces risk without creating a new one. A judge that returns a paragraph of hedging is not a judge; it is a second opinion no one can act on automatically.
Cost-Aware Routing: When the Judge Fires
The judge is the most capable tier and therefore the most expensive one. Running it on every decision is wasteful, because the vast majority of cases are clear-cut and do not need a second pair of eyes. The discipline of the pattern is to fire the judge selectively, on the cases where its judgment actually changes outcomes: verdicts that land near a decision boundary, and verdicts that are high-impact regardless of where they sit.
pipeline:
read: { llm: false } # parse + OCR, no model
fast_screen: { model: cheap, always: true } # gate: scores every case
analyze: { model: capable, thinking: true, when: "not cleared_by_fast_screen" }
score: { llm: false } # deterministic code computes the number
verify: { web: true } # external check + Bayesian update
judge: { model: strong, when: "risk > judge_threshold" } # high-risk only, bounded adjustment
The table encodes that logic declaratively. Reading runs on every file but uses no model. The fast screen runs on every case and acts as the gate: the comfortable low-risk tail is accepted there and never touches the expensive tiers. Analysis runs only on cases the screen did not clear, with an extended thinking budget. Scoring is deterministic code, so it is not a model call at all. The judge fires under one condition - the risk landing above a threshold - which concentrates it on exactly the high-impact, near-boundary cases where a wrong flip is expensive and the primary’s confidence is least trustworthy. Everything comfortably inside the low-risk region skips both the analysis model and the judge. This is how you get the reliability benefit of a second model without paying for it on every call. The cost-versus-capability trade-off across model tiers is explored further in Choosing AI Models for Security: A Practical Comparison.
Extended Thinking: Latency vs Consistency
Extended thinking - giving a model an explicit token budget to reason before it commits to an answer - is a tool, not a default. It is worth understanding when it pays for itself and when it is simply latency you bought for nothing.
The thinking budget earns its keep on borderline cases. When the evidence is mixed, when two interpretations both have support, or when the correct answer depends on weighing several weak signals against each other, the extra reasoning steps produce a more consistent and better-justified verdict. The model has room to surface the tension explicitly and resolve it deliberately rather than snapping to whichever conclusion the surface features suggest. On these inputs, the additional latency and token cost buy genuine consistency, which is the property you most need when the case is hard.
On clear-cut inputs the budget is wasted. If the evidence points unambiguously in one direction, a model will reach the right conclusion without extended deliberation, and the thinking tokens add latency and cost without changing the answer. The practical consequence is to spend the budget on the analysis tier where ambiguity concentrates and skip it on the fast-screen tier built for easy cases. Treating extended thinking as something you switch on for the hard tiers and off for the easy ones, rather than a global flag, is what keeps the pipeline both reliable and responsive.
Measuring a Judge
A judge you cannot measure is a judge you cannot trust. Three metrics describe its behavior, and the point of tracking them is method, not a leaderboard.
The first is agreement rate: the share of reviewed verdicts the judge accepts unchanged. The second is override rate: the share it changes, which is simply the complement of agreement on reviewed cases. The third is cost per decision: the blended inference cost across all tiers for an average case, which the routing rules are meant to keep bounded by firing the expensive judge selectively.
The override rate is the most diagnostic of the three, and the way to read it is by its extremes rather than any single “correct” value. An override rate that trends toward zero is a warning sign: the judge is decorative, agreeing with everything, adding cost and latency while catching nothing. That can mean the judge is being shown the primary’s reasoning and rubber-stamping it, or that the rubric is too permissive to ever disagree. An override rate that trends very high is the opposite warning: if the judge is constantly overturning the primary, the primary model is likely miscalibrated for the task, or the two tiers are working from different effective standards, and the real fix belongs upstream rather than in the judge.
To make this concrete without claiming any measured production figures: as an illustration, suppose a team observes that the judge overrides a small fraction of the verdicts it reviews, and that those overrides cluster on cases near the decision boundary. That shape - a modest, boundary-concentrated override rate - is the kind of pattern you would hope to see, because it means the judge is doing meaningful work exactly where the primary is least certain, and leaving the clear cases alone. The specific value that counts as healthy depends entirely on the domain and the rubric; the discipline is to baseline it, watch the trend, and investigate when it drifts toward either extreme. Treat any number you see in an example like this as a stand-in for the shape of the result, not as a benchmark to reproduce.
The Same Problem in Security Ops
The judge pattern is not specific to document analysis. It maps cleanly onto security operations, where the stakes are obvious and the failure modes are the same. Consider SIEM alert triage: an LLM reads an alert, correlates it with context, and proposes a disposition - escalate, investigate, or close. Letting a single model auto-close a critical alert is precisely the high-impact, low-tolerance-for-error situation the pattern is built for. A hallucinated “this is a known benign scanner” or a drifted sense of what counts as critical can mean a real intrusion is dismissed.
The tiered approach translates directly. A cheap model extracts and normalizes the alert fields. A mid-tier model correlates them against context and proposes a disposition with a confidence score. Low-severity, high-confidence benign alerts are dispatched by a fast screen so analysts are not buried. But any verdict that would auto-close a high-severity alert routes to a judge that re-evaluates the disposition against an explicit triage rubric, with no access to the first model’s narrative. Wazuh + AWS Bedrock MCP: Part 2 shows the tool-mediated, multi-step structure such a triage pipeline relies on.
The underlying lesson is the same in both domains. Reliability in an LLM decision system does not come from a single very capable model; it comes from structure - independent inputs, externalized rubrics, selective escalation, and measurement. The judge pattern is one concrete way to assemble those properties into a pipeline you can actually defend when a verdict is questioned.
Source of the Case Study
This pattern was developed while building GetPruf, a resume-fraud-detection pipeline. The code and figures here are illustrative; the structure is domain-agnostic and applies to any high-stakes LLM decision system.