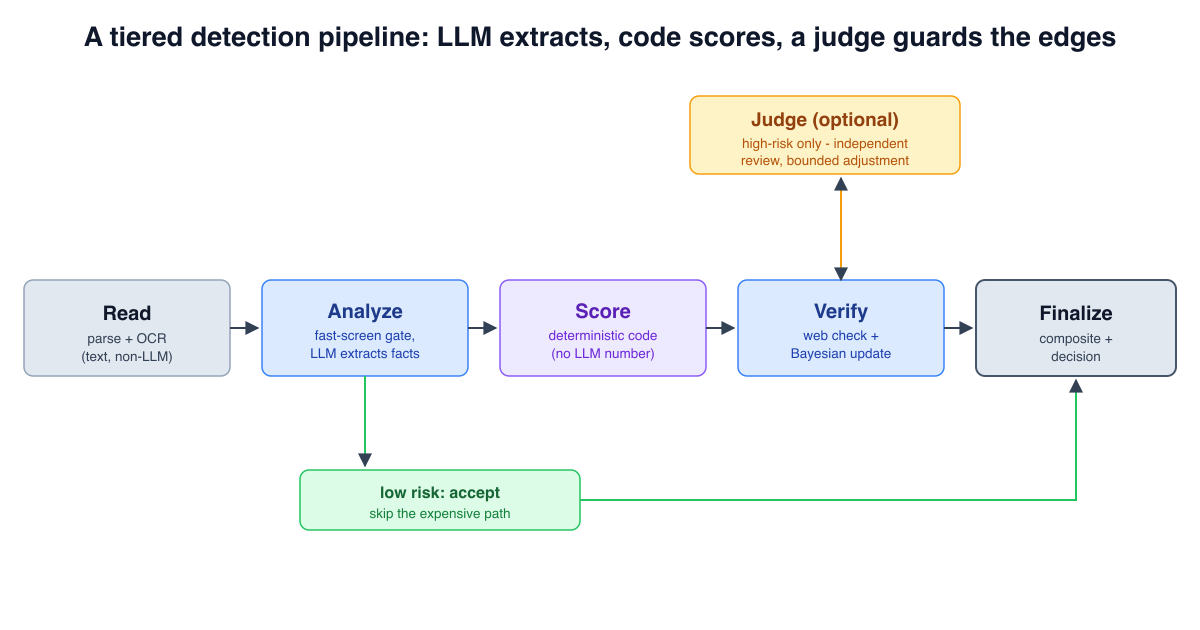
When a large language model returns a confident verdict - “this document is fraudulent”, “this alert is benign”, “this transaction is safe” - the natural instinct is to trust it. The model wrote a fluent rationale, cited the right fields, and reached a clean conclusion. The problem is that fluency is not correctness. In a low-stakes setting, an occasional wrong answer is noise. In a high-stakes pipeline, where a single verdict can deny someone a job, close a critical security incident, or release a fraudulent payment, the cost of a confident wrong answer is real and asymmetric.
[Read More]The Judge Pattern: Cross-Checking LLM Verdicts