Когда большая языковая модель возвращает уверенный вердикт - “этот документ поддельный”, “этот алерт безопасен”, “эта транзакция чистая” - первый инстинкт - довериться ему. Модель написала складное обоснование, сослалась на нужные поля и пришла к аккуратному выводу. Проблема в том, что складность не равна корректности. В системе с низкими ставками случайный неверный ответ - это просто шум. В пайплайне с высокими ставками, где один вердикт может лишить человека работы, закрыть критический инцидент безопасности или пропустить мошеннический платёж, цена уверенно неправильного ответа реальна и асимметрична.
Эта статья описывает паттерн, который борется именно с этой асимметрией - паттерн судьи. Вместо того чтобы доверять выводу одной модели, вы пропускаете высокозначимые решения через вторую, независимую модель, единственная задача которой - проверить первый вердикт по структурированной рубрике. Судья не переделывает работу с нуля. Он критически рассматривает вывод, соглашается или переопределяет его и объясняет своё решение. Паттерн не привязан к домену, но наиболее ценен именно там, где ошибки дорого обходятся.
Почему одиночные LLM-вердикты не работают в системах с высокими ставками
Три режима отказа повторяются достаточно часто, чтобы проектировать систему против них напрямую.
Первый - это галлюцинация фактов. Модель утверждает то, что не подтверждается данными: дату, которой никогда не было в источнике, работодателя, который не упоминается в документе, CVE, не совпадающий со строкой лога. Утверждение подаётся в том же уверенном тоне, что и корректное, поэтому у читателя дальше по пайплайну нет ни одного сигнала, что оно выдумано.
Второй - это дрейф рубрики. Когда одна и та же модель оценивает множество кейсов в множестве вызовов, её внутреннее ощущение того, где проходит порог, начинает блуждать. Один пограничный кейс оценивается как высокорисковый, а почти идентичный ему через несколько вызовов - как низкорисковый. Нет стабильного, вынесенного наружу стандарта - есть только то, что модель ощутила по каждому входу в отдельности. На большом объёме этот дрейф порождает несогласованные решения, которые сложно аудировать и ещё сложнее защитить.
Третий - это избыточная уверенность. Модели склонны выражать высокую уверенность даже тогда, когда исходные данные скудны или противоречивы. Калибровка - соответствие между заявленной уверенностью и фактической точностью - в целом плохая, и быстрее всего она деградирует именно на неоднозначных кейсах, где запас прочности нужен больше всего.
Заманчивое решение - спросить ту же модель ещё раз, возможно с другой температурой или с уточнением “ты уверена?”. Это не даёт настоящей независимости. Второй ответ берётся из тех же весов, того же распределения обучающих данных и нередко из той же формулировки промпта. Если первый ответ был неверным из-за систематического смещения - например, склонности перечитывать определённую фразу - то второй ответ, скорее всего, будет неверным в том же направлении. Ошибки коррелированы, а не независимы, поэтому усреднение или голосование большинством их не компенсирует. Настоящая перекрёстная проверка требует другой точки обзора - другой модели, другого промпта и, что критично, отсутствия доступа к рассуждениям первой модели.
Роли, а не модели: многоуровневая архитектура
Когда важна надёжность, инстинкт - взять “модель поумнее” везде. Это дорого и при этом упускает суть. Более полезная рамка - назначить каждому уровню свою задачу и выбрать самую дешёвую модель, которая хорошо с ней справляется. Сильная модель, потраченная на механическое извлечение, - это выброшенные на ветер деньги; дешёвая модель, которой поручают финальное высокозначимое решение, - это принятый на себя риск.

{kind=link}
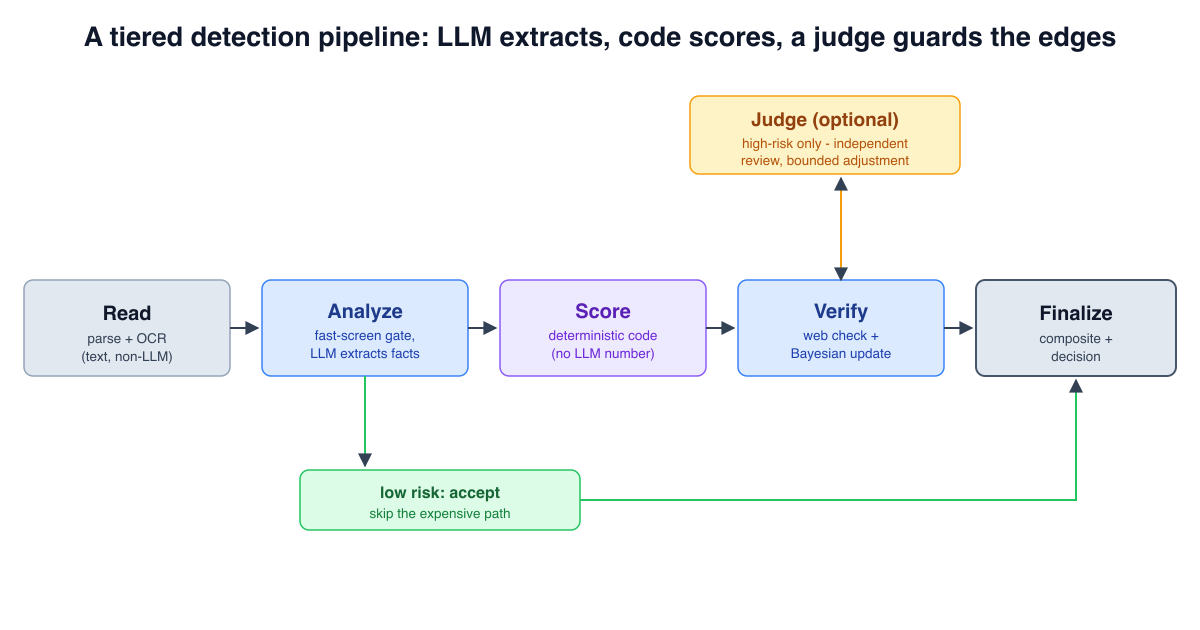
Многоуровневый пайплайн: у каждой стадии одна задача, score считает детерминированный код, а не модель, и опциональный судья перепроверяет только высокорисковые кейсы.
У каждой стадии свой отдельный контракт, и не все они являются вызовами модели. Чтение идёт первым и вообще не является LLM-шагом: парсер достаёт текст из документа, откатываясь на OCR, когда файл - это скан или фото без текстового слоя. Только после этого модель что-либо видит. Дешёвый быстрый скрининг оценивает каждый кейс и работает как гейт - кейсы, явно низкорисковые, принимаются как есть и пропускают всё, что идёт дальше, и именно отсюда берётся основная часть экономии. Кейсы, не прошедшие гейт, эскалируют на способную модель анализа, задача которой - извлечь структурированные факты и выявить тревожные моменты, желательно с бюджетом на extended thinking, потому что именно здесь концентрируется неоднозначность. Что важно, модель анализа не выдаёт финальное число: детерминированный шаг скоринга в обычном коде отображает извлечённые факты в риск-score, поэтому одни и те же факты всегда дают один и тот же score. Затем шаг верификации проверяет заявленные сущности по внешним источникам и корректирует score байесовским обновлением. И только после всего этого, и только на кейсах, которые всё ещё высокорисковые, запускается судья.
Ценность такого разделения двойная. Оно контролирует стоимость, потому что самая способная модель запускается только там, где её суждение действительно нужно. И оно контролирует распространение ошибок, потому что вывод каждого уровня ограничен и проверяем, а не является единым непрозрачным сквозным вызовом. Та же идея проявляется в инструментах безопасности: в статье Wazuh + AWS Bedrock: AI-безопасность в Docker (Часть 1) пайплайн разделяет извлечение, генерацию запроса и синтез на отдельные шаги, опосредованные инструментами, вместо того чтобы просить одну модель делать всё сразу.
Агент-судья: независимые входные данные, структурированная рубрика
Агент-судья - это сердце паттерна, и в его устройстве есть одно правило, которое важнее всех остальных: судья видит те же данные, что и основная модель, но он не видит цепочку рассуждений основной модели. Если вы передадите судье рассуждения первой модели, вы построите не рецензента, а штамп для одобрения. Судья читает убедительный нарратив, который уже приходит к выводу, и закрепляется на нём - и вы теряете независимость, которая была всей сутью затеи.
Поэтому судья получает данные и проверяемые выводы основной модели, которые он должен проверить - посчитанные scores и результаты верификации, - но не цепочку рассуждений модели анализа. Он оценивает их по явной, вынесенной наружу рубрике - письменному стандарту того, что считается высокорисковым, какие данные нужны для подтверждения каждого вывода и какие условия являются дисквалифицирующими. Затем он выдаёт небольшой структурированный результат: согласен ли он, ограниченную капом поправку к score в случае несогласия и обоснование. Поправка намеренно ограничена капом, поэтому один вызов судьи может сдвинуть пограничный вердикт, но никогда не может в одиночку его перевернуть - судья это проверка пайплайна, а не новая единая точка отказа.
def judge_review(evidence: dict, scores: dict, verification: dict) -> dict:
"""Independent review, fired only on high-risk cases. The judge sees
the evidence, the computed scores, and the verification results, but
never the analysis model's chain of thought - otherwise it just
rubber-stamps. Its score adjustment is clamped so one call cannot
flip a verdict on its own."""
prompt = build_judge_prompt(evidence, scores, verification)
review = call_model(JUDGE_MODEL, prompt, rubric=JUDGE_RUBRIC)
return {
"agrees": review.agrees,
"score_delta": clamp(review.score_delta, -CAP, +CAP),
"rationale": review.rationale,
}
Три проектных решения в этом скелете несущие. Первое: рубрика передаётся как явный параметр, а не зашита в общее ощущение суждения модели. Это прямая мера против дрейфа рубрики: стандарт живёт вне модели, в тексте под контролем версий, который можно рецензировать, тестировать и менять осознанно. Второе: вывод структурирован, а не является прозой - судья обязан зафиксировать agrees, конкретное значение score_delta и rationale, и это делает рецензию машиночитаемой, аудируемой и тривиальной для логирования. Третье: поправка ограничена фиксированным капом - судья может сдвинуть пограничный вердикт, но не может в одиночку перевернуть детерминированный score, поэтому добавление судьи снижает риск, а не создаёт новый. Судья, возвращающий абзац уклончивых формулировок, - это не судья; это второе мнение, по которому никто не может действовать автоматически.
Cost-aware routing: когда срабатывает судья
Судья - самый способный уровень и потому самый дорогой. Запускать его на каждом решении расточительно, потому что подавляющее большинство кейсов однозначны и не требуют второй пары глаз. Дисциплина паттерна в том, чтобы запускать судью выборочно - на тех кейсах, где его суждение реально меняет исход: на вердиктах, которые лежат рядом с границей принятия решения, и на вердиктах высокой значимости вне зависимости от того, где они расположены.
pipeline:
read: { llm: false } # parse + OCR, no model
fast_screen: { model: cheap, always: true } # gate: scores every case
analyze: { model: capable, thinking: true, when: "not cleared_by_fast_screen" }
score: { llm: false } # deterministic code computes the number
verify: { web: true } # external check + Bayesian update
judge: { model: strong, when: "risk > judge_threshold" } # high-risk only, bounded adjustment
Таблица кодирует эту логику декларативно. Чтение запускается на каждом файле, но не использует модель. Быстрый скрининг запускается на каждом кейсе и работает как гейт: комфортный низкорисковый хвост принимается здесь и никогда не касается дорогих уровней. Анализ запускается только на кейсах, которые скрининг не пропустил, с бюджетом на extended thinking. Скоринг - это детерминированный код, поэтому он вообще не является вызовом модели. Судья срабатывает при одном условии - оценка риска оказывается выше порога, - что концентрирует его ровно на высокозначимых пограничных кейсах, где неверный переворот дорог, а уверенности основной модели доверять можно меньше всего. Всё, что комфортно лежит внутри низкорисковой зоны, пропускает и модель анализа, и судью. Так вы получаете выигрыш в надёжности от второй модели, не платя за неё на каждом вызове. Компромисс между стоимостью и способностями по уровням моделей подробнее разобран в статье Выбор AI-моделей для безопасности: практическое сравнение.
Extended thinking: задержка против согласованности
Extended thinking - выдача модели явного бюджета токенов на рассуждение перед фиксацией ответа - это инструмент, а не значение по умолчанию. Стоит понимать, когда он окупается, а когда это просто задержка, купленная впустую.
Бюджет на рассуждение оправдывает себя на пограничных кейсах. Когда данные смешанные, когда у двух интерпретаций есть поддержка или когда правильный ответ зависит от взвешивания нескольких слабых сигналов друг против друга, дополнительные шаги рассуждения дают более согласованный и лучше обоснованный вердикт. У модели есть пространство явно выявить противоречие и осознанно его разрешить, а не сваливаться к тому выводу, на который намекают поверхностные признаки. На таких входах дополнительная задержка и стоимость токенов покупают настоящую согласованность - свойство, которое нужнее всего, когда кейс трудный.
На однозначных входах бюджет тратится впустую. Если данные недвусмысленно указывают в одну сторону, модель придёт к верному выводу без расширенного обдумывания, а токены рассуждения добавят задержку и стоимость, не меняя ответа. Практический вывод - тратить бюджет на уровне анализа, где концентрируется неоднозначность, и пропускать его на уровне fast-screen, построенном для лёгких кейсов. Относиться к extended thinking как к чему-то, что вы включаете на трудных уровнях и выключаете на лёгких, а не как к глобальному флагу, - именно это держит пайплайн одновременно надёжным и отзывчивым.
Как измерять судью
Судья, которого вы не можете измерить, - это судья, которому вы не можете доверять. Три метрики описывают его поведение, и смысл их отслеживания - метод, а не таблица рекордов.
Первая - уровень согласия (agreement rate): доля проверенных вердиктов, которые судья принимает без изменений. Вторая - уровень переопределений (override rate): доля, которую он меняет, что является просто дополнением к согласию на проверенных кейсах. Третья - стоимость на решение: смешанная стоимость инференса по всем уровням для среднего кейса, которую правила маршрутизации призваны держать ограниченной за счёт выборочного запуска дорогого судьи.
Уровень переопределений наиболее диагностичен из трёх, и читать его нужно по крайним значениям, а не по какому-то единственному “правильному” числу. Уровень переопределений, стремящийся к нулю, - это тревожный сигнал: судья декоративен, соглашается со всем, добавляет стоимость и задержку, не ловя ничего. Это может означать, что судье показывают рассуждения основной модели и он их штампует, или что рубрика слишком мягкая, чтобы хоть когда-то не согласиться. Очень высокий уровень переопределений - это противоположный сигнал: если судья постоянно переворачивает основную модель, та, вероятно, плохо откалибрована под задачу, либо два уровня работают по разным фактическим стандартам, и настоящее исправление лежит выше по пайплайну, а не в судье.
Чтобы сделать это конкретным, не претендуя ни на какие измеренные продакшен-цифры: в качестве иллюстрации предположим, что команда замечает, что судья переопределяет небольшую долю проверяемых вердиктов и что эти переопределения кластеризуются на кейсах вблизи границы принятия решения. Такая форма - умеренный, сосредоточенный у границы уровень переопределений - это тот паттерн, который хотелось бы видеть, потому что он означает, что судья делает осмысленную работу ровно там, где основная модель наименее уверена, и оставляет ясные кейсы в покое. Конкретное значение, которое считается здоровым, полностью зависит от домена и рубрики; дисциплина в том, чтобы зафиксировать базовую линию, следить за трендом и расследовать, когда он смещается к любой из крайностей. Любое число, которое вы видите в подобном примере, воспринимайте как заместитель формы результата, а не как бенчмарк для воспроизведения.
Та же задача в security ops
Паттерн судьи не специфичен для анализа документов. Он чисто переносится на операции безопасности, где ставки очевидны, а режимы отказа те же. Рассмотрим триаж алертов SIEM: LLM читает алерт, коррелирует его с контекстом и предлагает диспозицию - эскалировать, расследовать или закрыть. Позволять одной модели автоматически закрывать критический алерт - это ровно та высокозначимая ситуация с низкой терпимостью к ошибкам, под которую построен паттерн. Галлюцинированное “это известный безопасный сканер” или дрейфнувшее ощущение того, что считается критичным, может означать, что реальное вторжение будет отброшено.
Многоуровневый подход переносится напрямую. Дешёвая модель извлекает и нормализует поля алерта. Модель среднего уровня коррелирует их с контекстом и предлагает диспозицию с оценкой уверенности. Низкоприоритетные безопасные алерты с высокой уверенностью отправляются через fast-screen, чтобы аналитиков не заваливало. Но любой вердикт, который автоматически закрыл бы высокоприоритетный алерт, маршрутизируется к судье, который переоценивает диспозицию по явной рубрике триажа, без доступа к нарративу первой модели. Статья Wazuh + AWS Bedrock MCP: Часть 2 показывает опосредованную инструментами многошаговую структуру, на которую опирается такой пайплайн триажа.
Базовый урок одинаков в обоих доменах. Надёжность в системе принятия решений на LLM приходит не от одной очень способной модели; она приходит от структуры - независимых входных данных, вынесенных наружу рубрик, выборочной эскалации и измерения. Паттерн судьи - это один конкретный способ собрать эти свойства в пайплайн, который вы реально сможете защитить, когда вердикт поставят под сомнение.
Источник кейса
Этот паттерн был разработан в ходе создания GetPruf - пайплайна для детекции фрода в резюме. Код и цифры здесь иллюстративны; сама структура не привязана к домену и применима к любой системе принятия высокорисковых решений на LLM.